所以这次的《生成式人工智能服务管理办法(征求意见稿)》到底有多糟糕?
当然这个事情的热度早已过去,甚至于4月11号之后都看不到某用户人均年收入百万的社区的讨论了。我现在写出来,纯粹是因为作为Ph.D追赶死线的肌肉记忆,希望那个办公室的工作人员不要觉得我给他们增加了负担。
对于这个管理办法(的征求意见稿),批评自然是很多的,无论从纯技术的角度或者立法的角度,但是我今天站出来说它很糟糕,是要从形上学的角度,来讨论一下其中所约束的“提供者”的本质意义是什么。换句话来说,我认为这个征求意见稿中,对于他要管理的“提供者”到底是谁都讲不清楚,就直接伸出大棒去管理,这明显犯了有中国特色的只讲形式不究实质的错误。于是我便做了这么一个图来讨论,到底什么是“提供者”。
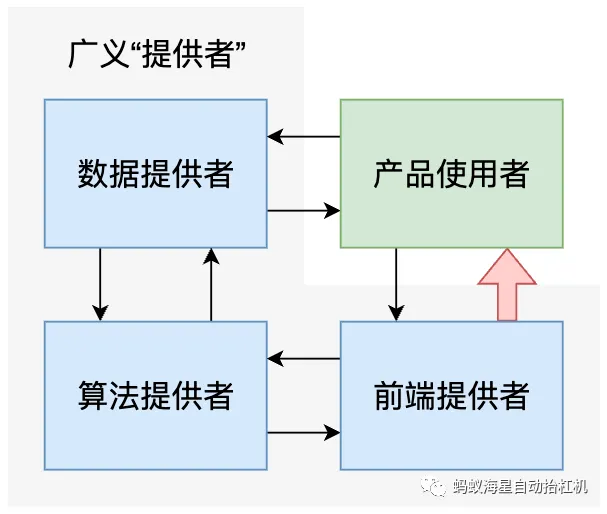
抛开更为底层的通用基础设施,仅从特化至“内容生成产品”的链路来看,提供者大致可以分为三个模块:
为了开发生成式人工智能而提供数据的模块
利用这些数据,进行生成式人工智能开发的模块
利用已经开发完成的产品,对外部用户直接提供服务的模块
这三个模块之间可以存在重叠但是不存在隶属,一个模块可以由多个单位运作,也存在一个单位同时提供多个模块的情况。例如,某家科创公司自己搜集数据并且开发模型,并将此模型以接口形式提供给多家公司/行政机关进行二次包装使用。此时,仅仅以此稿第五条所述“提供者”来约束这一系列行为,是会显得比较模糊而导致最终的权责不明的。以下则以图中四个模块之间的相互关系为基础,对此征求意见稿进行更为详细的分析:
数据=算法:这两者之间的关系通常来说比较清晰且技术化,数据被用来开发算法,算法则依据开发的结果对数据进行反馈。征求稿中对此相关的有第七条,第八条,主要对数据的来源的合法性上做了强制性的规定;并且在数据的质量上提出了一些“倡议”(我也不知道该怎么准确描述)。
首先,数据的质量并不需要基于行政管理进行优化,无论是独立的数据提供商或者是连带数据的算法开发者,都会有动力对其数据的真实性准确性等进行提升,特别是第八条,应当对基础合法性,或者价值正确性进行评价,而不是内容本身的正确性。
其次,对于合法性的直接责任,应当依照真实的数据获取与使用的链路进行合理地分配,而非仅针对广义的“提供者”。对于不具有合法性的来源,或者针对用户个人信息的来源,应当确实需要负责的单位。例如,某独立数据提供商将含有危害国家安全的内容提供给多个算法开发者,则应该只追究数据提供商的责任,而非追究所有使用此数据进行开发的单位的责任。
算法=前端:虽然当下各大科技公司的产品均呈现出一家将全链路都完成的形式,但是在现实中依旧需要区分某个广义的“提供者”是否具有自我实现算法的能力。征求稿中对此这两者之间的关系定义目前极为模糊,相关的有第四条,第五条,第十五条,第十六条。
第四条是一个很有意思的条款,特别是第二款,很显然它在尝试通过行为定义何为“提供者”,但是从“算法设计”这样的描述可以体会到,其想要约束的更多是算法提供者,而将数据与前端都定义为算法提供者的上下游行为。而其第四款,显然也是在将主体的责任定义在算法提供者上,而对单独的前端服务提供者没有额外的要求。这种定义会模糊这一个强制性的规定的适用性,让算法提供者承担过多的责任。
第五条承接了第四条中的概括性“提供者”定义,且随后额外点明了算法提供者与前端服务者不是同一单位主体的可能性(前端服务者使用可编程接口进行服务),但是在描述过程中也是倾向于算法提供者为主体责任者,而并不明确追究其下游前端服务者的具体责任。
第十五条十六条,本质上是一个前端提供者反馈算法提供者的机制,显然仅使用其他单位提供算法的前端服务提供者,是没有能力进行3个月内的合规要求的。所以这里应当明确两者的责任划分,对于前端提供者要求采取内容过滤,而对于算法的优化要求,则应当另外做规定。
前端=用户:前端与用户之间的关系这更符合这次征求意见稿中大多数条款的书写基调,简单概括来讲,前端提供者应当对其提供的内容以及用户的使用情况负责,用户应当有渠道对其所利用之前端服务进行反馈。主要牵扯到的条款则为第九条,第十条,第十一条,第十二条,第十三条,第十四条,第十七条,第十八条,第十九条。
这些条款显然不应该针对算法提供者,特别是第九条,第十条,第十八条,这些条款应当针对前端服务提供者将其适用范围特化。
牵扯到可能的用户的反馈相关的第十一条, 第十二条,第十三条,第十七条,则应该强化责任至算法与前端提供者两方。
用户=数据:用户与数据提供者的关系会更加疏远一些,但是实质上会存在数据提供者利用灰色地带搜集用户的使用数据,并且可能会对用户主动提供反馈数据进行奖励。这里主要牵扯到的条款有第七条,第十一条与第十七条。
第七条虽然有规定有关个人信息的保护措施,但是个人信息之定义则应当明确,第十一条中虽然提供了部分定义,但是这显然难以充分保护用户在使用时受到的个人信息安全等问题。
第十七条中虽然定义了广义“提供者”应当有的透明公开义务,但是其前提却为“应某某之要求”,而这显然应当在本管理办法中明确提及。
最后再提一些建议用以解决“提供者”本体定义的问题,首先最合理的方式应当是明确提供者的各个模块的责任,将对应的条款与罚则明确对象目标,这样最大的一个优点是可以帮助单纯的算法提供者解绑责任,使其在我国本就处在追赶状态的生成式人工智能中获得保护;其次则可以通过修改第六条,将概括性的“提供者”进行明确化,例如算法备案时区分数据、算法、前端三种不同的“提供者”,并对其进行区分管理。
我知道你们肯定不爱看,所以欢迎直接找我来讨论,我讲人话与你们辩证。
Enjoy Reading This Article?
Here are some more articles you might like to read next: